PR CENTER
PR센터
![]()
![]() PR센터
PR센터![]() 보도자료
보도자료
보도자료
| [GIGABYTE] 제너레이티브 AI를 활용하려면 "훈련"과 "추론"에 대해 배워야 합니다 | |
|---|---|
| 작성자 : 관리자( ) 작성일 : 2023.07.04 조회수 : 169 | |
| 첨부파일 |
o202306291803469412.jpg |
 바위 밑에서 살지 않았다면 ChatGPT와 같은 챗봇이 러브레터에서 소네트에 이르기까지 무엇이든 작곡할 수 있는 방법과 Stable Diffusion과 같은 텍스트-이미지 모델이 텍스트 프롬프트를 기반으로 아트를 렌더링할 수 있는 방법과 같은 생성 AI의 "마법"에 대해 잘 알고 있어야 합니다. 사실, 생성형 AI는 이해하기 쉬울 뿐만 아니라 작업하기도 쉽습니다. 최신 기술 가이드에서는 생성형 AI의 "훈련" 및 "추론" 프로세스를 분석하고 잠재력을 최대한 활용할 수 있는 GIGABYTE Technology의 토털 솔루션을 권장합니다.
물론 생성형 AI는 실제로 붓을 들고 있는 로봇이 아닙니다. 그러나 이 연상시키는 이미지는 AI의 미래가 얼마나 사랑스럽고 유능하며 영감을 줄 수 있는지를 나타냅니다.
교육: 작동 방식, 사용 도구, GIGABYTE의 지원 방법
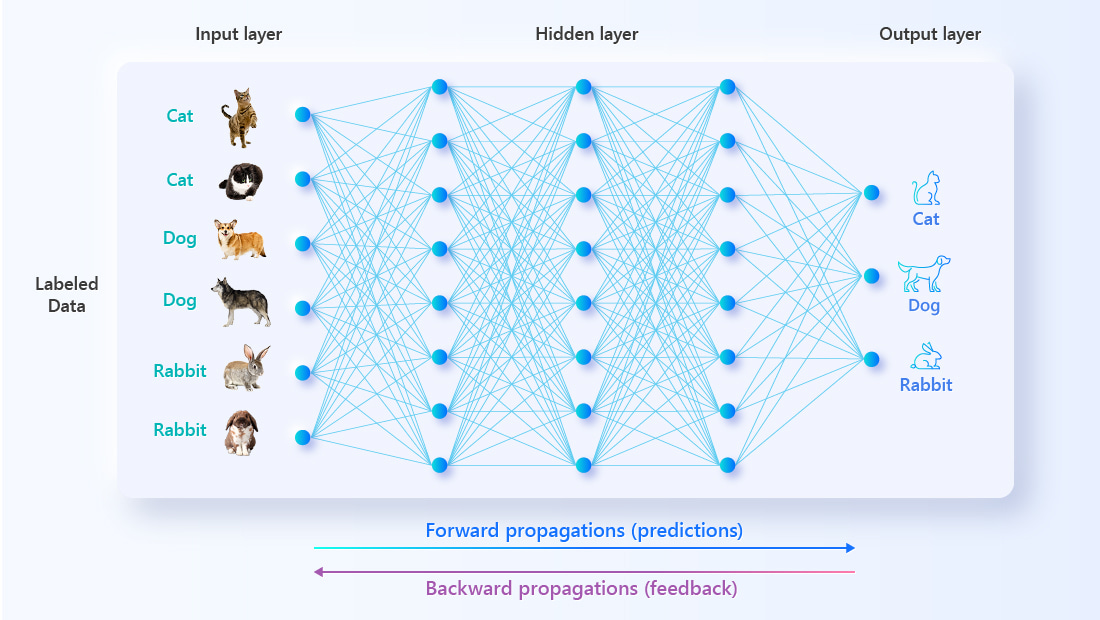 일반적으로 AI 훈련 과정에서 레이블이 지정된 데이터의 바다가 알고리즘에 쏟아져 "연구"됩니다. AI는 추측을 한 다음 정확성을 높이기 위해 답을 확인합니다. 시간이 지남에 따라 AI는 추측에 능숙해져서 항상 정확한 추측을 할 것입니다. 즉, 작업하기를 원하는 정보를 "학습"한 것입니다.
 GIGABYTE의 G593-SD0 및 G593-ZD2는 각각 가장 진보된 4세대 Intel® Xeon® 및 AMD EPYC™ 9004 CPU와 NVIDIA의 HGX™ H100 컴퓨팅 모듈을 5U 섀시 내부에 통합합니다. 이것은 지구상에서 가장 강력한 AI 컴퓨팅 플랫폼 중 하나이며 AI 교육 설정의 핵심이 될 수 있습니다.
추론: 작동 방식, 사용할 도구 및 GIGABYTE가 도울 수 있는 방법
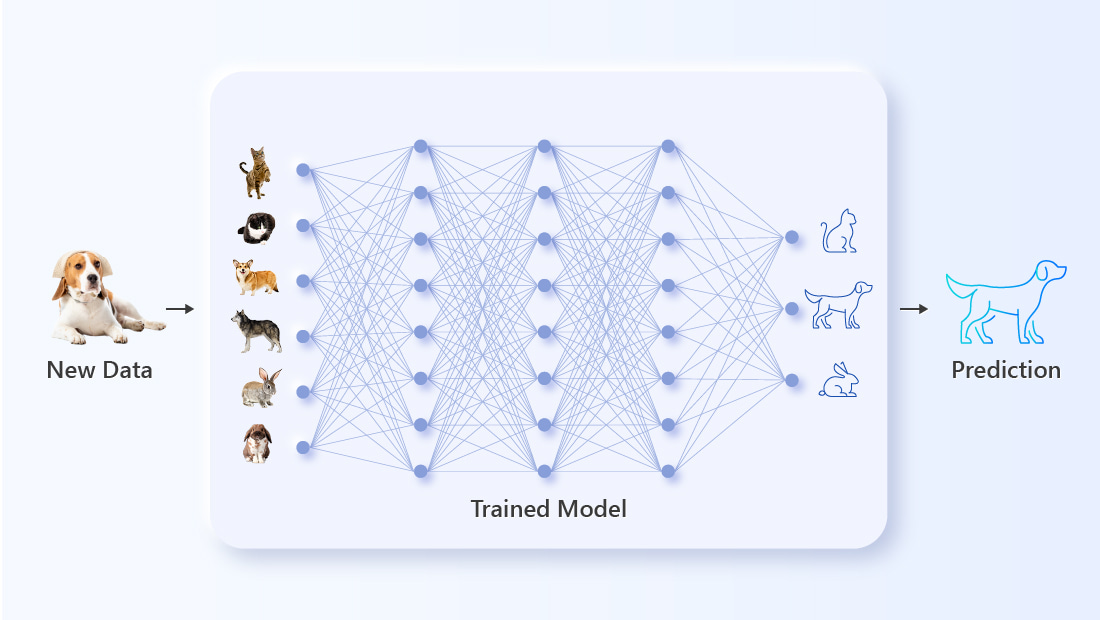 AI 추론 프로세스 중에 익숙하지 않고 레이블이 지정되지 않은 입력이 미리 학습된 모델에 공급됩니다. AI는 새 데이터의 매개 변수를 훈련과 비교하고 올바른 예측을 시도합니다. 추론 단계의 성공과 실패는 AI를 더욱 개선하기 위해 다음 학습 세션에서 사용됩니다.
 GIGABYTE의 G293-Z43은 소형 70U 섀시에 업계 최고 수준의 초고밀도 AMD Alveo™ V2 추론 가속기 카드 <>개를 제공합니다. 이 설정은 뛰어난 성능과 에너지 효율성을 제공할 뿐만 아니라 대기 시간을 단축합니다. 이러한 고밀도 구성은 GIGABYTE의 독자적인 서버 냉각 기술에 의해 가능합니다.
|
|
| 이전글 | [AAEON] 얼굴 인식에 엣지 도입 |
| 다음글 | [GIGABYTE] 실리콘 밸리 스타트업 Sushi Cloud, GIGABYTE와 함께 베어메탈 서비스 출시 |

